Auto-adjust `-remoteWrite.concurrency` cmd-line flags with the number of
available CPU cores in the same way as vmagent does. With this change
the default behavior of vmalert in high-loaded installation should
become more resilient. This change also reduces
`-remoteWrite.flushInterval` from `5s` to `2s` to provide better data
freshness.
---------
Signed-off-by: hagen1778 <roman@victoriametrics.com>
Co-authored-by: Nikolay <nik@victoriametrics.com>
This commit properly adds `group_name` and `file` fields for recording rules web api response at `/api/v1/rules`.
Previously these fields were blank.
Related issue https://github.com/victoriaMetrics/victoriaMetrics/issues/7297
Signed-off-by: Antoine Deschênes <antoine.deschenes@linux.com>
### Describe Your Changes
- release 1.17.2 updates
- added sections on logging and CLI args to docs
### Checklist
The following checks are **mandatory**:
- [x] My change adheres [VictoriaMetrics contributing
guidelines](https://docs.victoriametrics.com/contributing/).
### Describe Your Changes
Changed highlight style for cmd flags
### Checklist
The following checks are **mandatory**:
- [ ] My change adheres [VictoriaMetrics contributing
guidelines](https://docs.victoriametrics.com/contributing/).
### Describe Your Changes
docs/vmanomaly: release 1.17.1
### Checklist
The following checks are **mandatory**:
- [ ] My change adheres [VictoriaMetrics contributing
guidelines](https://docs.victoriametrics.com/contributing/).
### Describe Your Changes
Add support for
https://github.com/VictoriaMetrics/VictoriaMetrics/issues/6930
Calculate `-search.maxUniqueTimeseries` by
`-search.maxConcurrentRequests` and remaining memory if it's **not set**
or **less equal than 0**.
The remaining memory is affected by `-memory.allowedPercent`,
`-memory.allowedBytes` and cgroup memory limit.
### Checklist
The following checks are **mandatory**:
- [x] My change adheres [VictoriaMetrics contributing
guidelines](https://docs.victoriametrics.com/contributing/).
---------
Signed-off-by: hagen1778 <roman@victoriametrics.com>
Co-authored-by: Roman Khavronenko <roman@victoriametrics.com>
(cherry picked from commit 85f60237e2)
Signed-off-by: hagen1778 <roman@victoriametrics.com>
Group
[sleeps](daa7183749/app/vmalert/rule/group.go (L320))
random duration before start the evaluation, and during the sleep,
`g.updateCh <- new` will be blocked since there is no `<-g.updateCh`
waiting.
---------
Signed-off-by: hagen1778 <roman@victoriametrics.com>
Co-authored-by: hagen1778 <roman@victoriametrics.com>
### Describe Your Changes
**Added ability to hide the hits chart**
- Users can now hide or show the hits chart by clicking the "eye" icon
located in the upper-right corner of the chart.
- When the chart is hidden, it will stop sending requests to
`/select/logsql/hits`.
- Upon displaying the chart again, it will automatically refresh. If a
relative time range is set, the chart will update according to the time
period of the logs currently being displayed.
**Hits chart visible:**
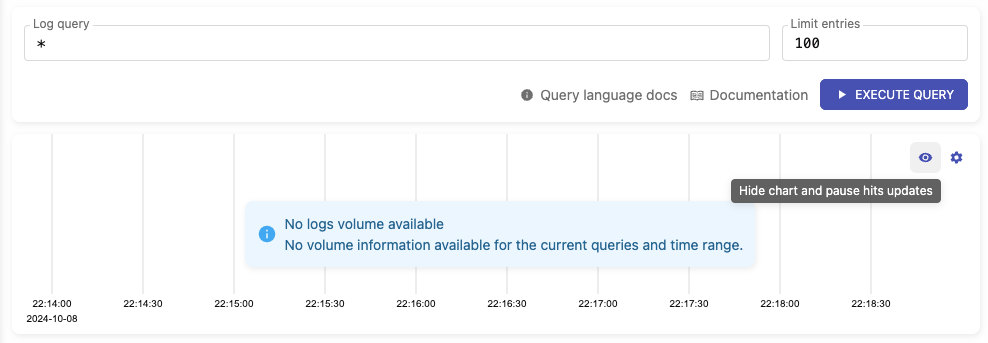
**Hits chart hidden:**

Related issue: #7117
### Checklist
The following checks are **mandatory**:
- [ ] My change adheres [VictoriaMetrics contributing
guidelines](https://docs.victoriametrics.com/contributing/).
Co-authored-by: Aliaksandr Valialkin <valyala@victoriametrics.com>
### Describe Your Changes
Fixed the display of hits chart in VictoriaLogs.
See #7133
### Checklist
The following checks are **mandatory**:
- [ ] My change adheres [VictoriaMetrics contributing
guidelines](https://docs.victoriametrics.com/contributing/).
Unpack the full columnsHeader block instead of unpacking meta-information per each individual column
when the query, which selects all the columns, is executed. This improves performance when scanning
logs with big number of fields.
- Use parallel merge of per-CPU shard results. This improves merge performance on multi-CPU systems.
- Use topN heap sort of per-shard results. This improves performance when results contain millions of entries.
### Describe Your Changes
When debugging unexpected query results, add reduce_mem_usage=1 param to
export query to preserve duplicates.
### Checklist
The following checks are **mandatory**:
- [x] My change adheres [VictoriaMetrics contributing
guidelines](https://docs.victoriametrics.com/contributing/).
Signed-off-by: Artem Fetishev <rtm@victoriametrics.com>
### Describe Your Changes
docs/vmanomaly: release v1.17.0
### Checklist
The following checks are **mandatory**:
- [x] My change adheres [VictoriaMetrics contributing
guidelines](https://docs.victoriametrics.com/contributing/).
After adding multitenant query feature at v1.104.0, searchQuery wasn't
properly unmarshalled at bottom vmselect in multi-level cluster setup.
It resulted into empty query responses.
This commit adds fallback to Unmarshal method of SearchQuery to fill
TenantTokens. It allows to properly execute search requests
at vmselect side.
Related issue:
https://github.com/VictoriaMetrics/VictoriaMetrics/issues/7270
---------
Signed-off-by: f41gh7 <nik@victoriametrics.com>
Co-authored-by: Roman Khavronenko <roman@victoriametrics.com>
### Describe Your Changes
Add more detailed information about performing backups for
VictoriaMetrics cluster setup.
More detailed explanation should help to address questions similar to
https://github.com/VictoriaMetrics/VictoriaMetrics/issues/7225
### Checklist
The following checks are **mandatory**:
- [x] My change adheres [VictoriaMetrics contributing
guidelines](https://docs.victoriametrics.com/contributing/).
Signed-off-by: Zakhar Bessarab <z.bessarab@victoriametrics.com>
Previously unit `m` is not correctly supported.
---------
Signed-off-by: hagen1778 <roman@victoriametrics.com>
Co-authored-by: hagen1778 <roman@victoriametrics.com>
### Describe Your Changes
If a dict flag has only one value without a prefix it is supposed to
replace default value.
Previously, when flag was set to `-flag=2` and the default value in
`NewDictInt` was set to 1 the resulting value for any `flag.Get()` call
would be 1 which is not expected.
This commit updates default value for the flag in case there is only one
entry for flag and the entry is a number without a key.
This affects cluster version and specifically `replicationFactor` flag
usage with vmstorage [node
groups](https://docs.victoriametrics.com/cluster-victoriametrics/#vmstorage-groups-at-vmselect).
Previously, the following configuration would effectively be ignored:
```
/path/to/vmselect \
-replicationFactor=2 \
-storageNode=g1/host1,g1/host2,g1/host3 \
-storageNode=g2/host4,g2/host5,g2/host6 \
-storageNode=g3/host7,g3/host8,g3/host9
```
Changes from this PR will force default value for `replicationFactor`
flag to be set to `2` which is expected as the result of this
configuration.
---------
Signed-off-by: Zakhar Bessarab <z.bessarab@victoriametrics.com>
address https://github.com/VictoriaMetrics/VictoriaMetrics/issues/6970.
This reduces the hard limit on duration for completing the test when
users run vmalert-tool on slow hosts.
---------
Signed-off-by: hagen1778 <roman@victoriametrics.com>
Co-authored-by: hagen1778 <roman@victoriametrics.com>
1. Verify if field in [fields
pipe](https://docs.victoriametrics.com/victorialogs/logsql/#fields-pipe)
exists. If not, it generates a metric with illegal float value "" for
prometheus metrics protocol.
2. check if multiple time range filters produce conflicted query time
range, for instance:
```
query: _time: 5m | stats count(),
start:2024-10-08T10:00:00.806Z,
end: 2024-10-08T12:00:00.806Z,
time: 2024-10-10T10:02:59.806Z
```
must give no result due to invalid final time range.
---------
Co-authored-by: Aliaksandr Valialkin <valyala@victoriametrics.com>
It has been appeared that VictoriaLogs is frequently used for collecting logs with tens of fields.
For example, standard Kuberntes setup on top of Filebeat generates more than 20 fields per each log.
Such logs are also known as "wide events".
The previous storage format was optimized for logs with a few fields. When at least a single field
was referenced in the query, then the all the meta-information about all the log fields was unpacked
and parsed per each scanned block during the query. This could require a lot of additional disk IO
and CPU time when logs contain many fields. Resolve this issue by providing an (field -> metainfo_offset)
index per each field in every data block. This index allows reading and extracting only the needed
metainfo for fields used in the query. This index is stored in columnsHeaderIndexFilename ( columns_header_index.bin ).
This allows increasing performance for queries over wide events by 10x and more.
Another issue was that the data for bloom filters and field values across all the log fields except of _msg
was intermixed in two files - fieldBloomFilename ( field_bloom.bin ) and fieldValuesFilename ( field_values.bin ).
This could result in huge disk read IO overhead when some small field was referred in the query,
since the Operating System usually reads more data than requested. It reads the data from disk
in at least 4KiB blocks (usually the block size is much bigger in the range 64KiB - 512KiB).
So, if 512-byte bloom filter or values' block is read from the file, then the Operating System
reads up to 512KiB of data from disk, which results in 1000x disk read IO overhead. This overhead isn't visible
for recently accessed data, since this data is usually stored in RAM (aka Operating System page cache),
but this overhead may become very annoying when performing the query over large volumes of data
which isn't present in OS page cache.
The solution for this issue is to split bloom filters and field values across multiple shards.
This reduces the worst-case disk read IO overhead by at least Nx where N is the number of shards,
while the disk read IO overhead is completely removed in best case when the number of columns doesn't exceed N.
Currently the number of shards is 8 - see bloomValuesShardsCount . This solution increases
performance for queries over large volumes of newly ingested data by up to 1000x.
The new storage format is versioned as v1, while the old storage format is version as v0.
It is stored in the partHeader.FormatVersion.
Parts with the old storage format are converted into parts with the new storage format during background merge.
It is possible to force merge by querying /internal/force_merge HTTP endpoint - see https://docs.victoriametrics.com/victorialogs/#forced-merge .
Previously it was incorrectly used append for pre-allocated slice of labels.
This commit fixes slice append by allocating zero length slice with needed capacity.
---------
Co-authored-by: Nikolay <nik@victoriametrics.com>